When it comes to home theater, a lot of people think big -- a big picture and lots of sound coming from a widescreen TV and an array of speakers. But the typical home-theater setup, with its surround-sound speakers and subwoofer, won't work for every home. Some people don't have enough room for all of that equipment. Others don't want their living rooms cluttered with cables, or they don't want the hassle of adjusting the placement and height of lots of speakers.
That's where virtual surround sound comes in. It mimics the effect of a multi-speaker surround-sound system, but it uses fewer speakers and fewer cables. These systems come in two primary varieties -- 2.1 surround and digital sound projection. Most of the time, 2.1-surround systems use two speakers placed in front of the listener and a subwoofer placed somewhere else in the room. These recreate the effect of a 5.1 surround-sound system, which has five speakers and a subwoofer. Digital sound projectors, on the other hand, tend to use a single strip of small speakers to produce sound. Many digital sound projectors do not include a subwoofer.
Advertisement
Regardless of their exact setup, these systems work on the same basic principles. They use a number of techniques to modify sound waves so that they seem to come from more speakers than are really there. These techniques came from the study of psychoacoustics, or the manner in which people perceive sound. In this article, we'll explore the traits of human hearing that allow two speakers to sound like five, as well as what to keep in mind if you shop for a virtual surround-sound system.
Virtual surround-sound systems take advantage of the basic properties of speakers, sound waves and hearing. A speaker is essentially a device that changes electrical impulses into sound. It does this using a diaphragm -- a cone that rapidly moves back and forth, pushing against and pulling away from the air next to it. When the diaphragm moves outward, it creates a compression, or area of high pressure, in the air. When it moves back, it creates a rarefaction, or area of lower pressure. You can learn more about the details in How Speakers Work.
Compressions and rarefactions are the result of the movement of air particles. When the particles push against each other, they create an area of higher pressure. These particles also press against the molecules next to them. When the particles move apart, they create an area of lower pressure while pulling away from the neighboring particles. In this manner, the compressions and rarefactions travel through the air as a longitudinal wave.
Advertisement
When this wave of high- and low-pressure areas reaches your ear, several things happen that allow you to perceive it as sound. The wave reflects off of the pinna, or external cone, of your ear. This part of your ear is also known as the auricle. The sound also travels into your ear canal, where it physically moves your tympanic membrane, or eardrum. This sets off a chain reaction involving many tiny structures inside your ear. Eventually, the vibrations from the wave of pressure reach your cochlear nerve, which carries them to the brain (brain.htm) as nerve impulses. Your brain interprets these impulses as sound. How Hearing Works (hearing.htm) has lots more information about your ear's internal structures and what it takes to perceive sound.
Your brain's interpretation process allows you to understand the sound's meaning. If the sound is a series of spoken words, you can put them together into an understandable sentence. If the sound is a song, you can interpret the words, experience the tone and rhythm, and decide whether you like what you hear. You can also remember whether you've heard the same song or similar songs before.
In addition to allowing you to interpret the sound, your brain also uses lots of aural cues to help you figure out where it came from. This isn't always something you think about or are even consciously aware of. But being able to locate the source of a sound is an important skill. This ability helps animals locate food, avoid predators and find others of their species. Being able to tell where a sound came from also helps you decide whether someone is following you and whether a knock outside is at your door or your neighbor's.
These cues and the physical properties of sound waves are central to virtual surround sound. We'll look at them in more detail next.
Dolby Virtual Speaker
One method for creating a virtual surround-sound environment is . is a set of rules and algorithms that re-create multi-channel sound for devices that have only two ordinary speakers. It's a feature found in certain TVs, stereo systems, and computers rather than a separate, physical component of a home-theater system. A similar technology is Dolby Headphone, which uses sound-processing algorithms to let a normal set of headphones mimic a set of surround-sound speakers. You can learn more about other Dolby technologies in How Movie Sound Works.
Advertisement
Sound Cues and Virtual Surround Sound
Most people have had the experience of sitting in a very quiet room, like a classroom during a test, and having the silence broken by an unexpected noise, like change falling from someone's pocket. Usually, people immediately turn their heads toward the source of the sound. Turning toward the sound seems almost instinctive -- in an instant, your brain determines the sound's location. This is often true even if you can only hear in one ear.
A person's ability to pinpoint a sound's location comes from the brain's analysis of the sound's attributes. One attribute has to do with the difference between the sound that your right ear hears and the sound that your left ear hears. Another has to do with the interactions between the sound waves and your head and body. Together, these are the aural cues that the brain uses to figure out where a sound came from.
Advertisement
Imagine that the coins in our quiet classroom example hit the floor somewhere to your right. Because the sound travels as physical waves through the air -- a process that takes time -- it reaches your right ear a fraction of a second before it reaches your left. In addition, the sound is a little quieter by the time it reached your left ear. This reduction in volume is because of the natural dissipation of the sound wave and because your head absorbs and reflects a little bit of the sound. The difference in volume between your left and right ears is the interaural level difference (ILD). The delay is the interaural time difference (ITD).
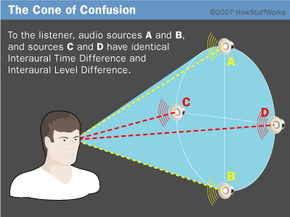
Time and level differences give your brain a clear idea of whether a sound came from your left or your right. However, these differences carry less information about whether the sound came from above you or below you. This is because changing the elevation of a sound affects the path it takes to reach your ear, but it doesn't affect the difference between what you hear in your left and right ears. In addition, it can be hard to figure out whether a sound is coming from in front of you or behind you if you're only relying on time and level differences. This is because, in some cases, these sounds can produce identical ILDs and ITDs. Even though the sounds are coming from a different location, the differences in what your ears hear are still the same. The ILDs and ITDs are identical in a cone-shaped area extending outward from your ear known as the cone of confusion.
ILDs and ITDs require people to be able to hear in both ears, but people who cannot hear in one ear can still often determine the source of sound. This is because the brain can use the sound's reflection off of the surfaces in one ear to try to localize the sound's source.
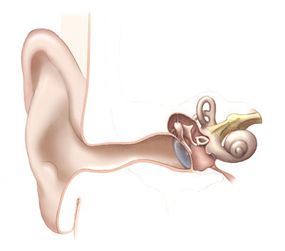
Your brain can use a sound wave's reflection off of the pinna, or auricle, of your ear to determine the sound's location.
Image courtesy National Institute on Deafness and Other Communication Disorders
When a sound wave reaches a person's body, it reflects off of the person's head and shoulders. It also reflects off of the curved surface of the person's outer ear. Each of these reflections makes subtle changes to the sound wave. The reflecting waves interfere with one another, causing parts of the wave to get bigger or smaller, changing the sound's volume or quality. These changes are known as head-related transfer functions (HRTFs). Unlike with ILDs and ITDs, the sound's elevation, or the angle at which it hits your ears from above or below, affects its reflections of the surfaces of the body. The reflections are also different depending on whether the sound comes from in front of or behind your body.
HRTFs have a subtle but complex effect on the shape of the wave. The brain interprets these differences in the wave's shape, using them to find the sound's origin. We'll look at how researchers have studied this phenomenon and used it to create virtual surround-sound systems in the next section.
Advertisement
Studying Sound Reflections
The auricle of a person's ear has lots of surfaces that can reflect sound waves. Most of these surfaces are curved. Some might direct the sound toward other surfaces in the ear, causing the wave to bounce more than once before reaching the tympanic membrane. Interactions with a person's face, head, hair and torso are complicated as well. Attempting to isolate and measure each of these reflections by hand would be almost impossible. For this reason, scientists have studied head-related transfer functions (HRTFs) using sound sources, lots of microphones and computer programs.
In some cases, researchers have attached tiny microphones to the surfaces of human participants' bodies. In others, they have used lifelike mannequins designed to accurately represent a person's skin, cartilage and body proportions. One such mannequin is the Knowles Electronic Manikin for Acoustic Research, or KEMAR, which has been used in HRTF research in laboratories such as the MIT Media Lab.
Advertisement
These microphones have one job - to capture sound. Computers can then analyze subtle differences in sounds with different points of origin or in the way a single sound interacts with different parts of the body. Eventually, this information leads to an algorithm or set of algorithms. The algorithm is essentially a group of rules that describes the way the HRTFs and other factors changed the shape of the sound wave. Applying the algorithm to another sound wave changes its shape as well, giving it the same properties that the first wave had after it interacted with the person's body.
Algorithms like these are at the heart of virtual surround-sound systems. Here's what happens:
Researchers use microphones to capture and study the sound from a 5.1-surround speaker setup. Often, the research includes ears and bodies with lots of different shapes and sizes to help determine how different people perceive the same sound.
With the help of a computer, researchers develop an algorithm that can re-create this sound.
Researchers apply this 5.1-channel algorithm to a two-speaker system, recreating a sound field with the shape that a real 5.1-channel speaker system would emit.
A Polk 5.1 surround-sound SurroundBar
Image courtesy Polk Audio
In other words, the process applies aural cues to the sound wave, fooling your brain into interpreting the sound as though it came from five sources instead of two.
Advertisement
Virtual Surround Sound Tools and Techniques
A Sony 2.1 surround-sound system with subwoofer and receiver/amplifier
Image courtesy Consumer Guide Products
In addition to sound waves' interactions with the human body, virtual surround-sound speakers use a number of tools and techniques to create the illusion of 5.1-channel sound. Some systems, particularly digital sound-processing systems, physically reflect sound waves off of the walls of the room. In this case, some of the sound seems to come from behind you because it is bouncing off of the wall behind your head. Systems like these often require you to provide the dimensions of your room or to calibrate the speakers using a microphone. Otherwise, the reflections may happen at the wrong angles or in the wrong places.
Many two-speaker systems also incorporate crosstalk cancellation. This is basically the creative use of destructive interference to eliminate unwanted interference between the sound you should hear with your left ear and the sound you should hear with your right. This makes it less likely that your ears will pick up on one another's cues, ruining the illusion of five-speaker sound.
Advertisement
The algorithms and crosstalk cancellation protocols require the help of a computer processor, usually found in a receiver/amplifier. This device includes a sound-processing chip that can apply the algorithms to the sound waves in real time. As with other amplifiers, it receives the sound information from a source, like a satellite box or a DVD player. It applies the algorithms and makes any other adjustments to volume or sound quality before sending the signal to the speakers. In some systems, this receiver/amplifier is built in to the speaker units.
The biggest drawback to virtual surround-sound systems is that their immersive effect is an illusion rather than the product of multiple speakers. Maintaining this illusion requires you to sit in the right spot and to look directly at the television screen. Moving too far to the left or the right of the sweet spot can disrupt the sensation of real surround sound, placing you outside of the directed sound field. Sometimes, sounds that move from one side of the room to the other or from in front of you to behind you seem to be interrupted or sound unnatural. Since the sound waves themselves are only coming from two speakers, the sound field often has less power and impact than one from a full set of speakers.
In addition, there are a few points to keep in mind if you are shopping for a virtual surround-sound system:
Room size and shape: Since they tend to take advantage of sound reflections, digital sound projection systems often do not work very well in extremely large, open rooms or in rooms with irregularly-shaped walls.
Desired effect: If you're looking for full, room-filling sound, a two-speaker system may not be able to live up to your expectations.
Subwoofer: 2.1 systems include a subwoofer. Many digital sound-projection systems don't, but you can purchase one if you want additional bass sound.
Setup requirements: Many virtual surround-sound systems allow you to simply plug in your speakers and go. However, some require a calibration step that may involve measuring the room.
Price: Some 2.1-surround systems can be an affordable alternative to 5.1- or 7.1- surround systems. However, high-end digital sound-projection systems can cost more than $1500.
To learn more about virtual surround sound and related topics, check out the links on the next page.
Burkhead, M.D. "Manikin Measurements." Industrial Research Products, Inc. (5/15/2007). http://www.knowleselectronics.com/images/products/pdf/ KEMAR_Manikin_Measurements.pdf
Coppin, Sarah, et al. "Sound Localization Using Head Transfer Functions." Rice University. (5/15/2007). http://www.ece.rice.edu/~crozell/courseproj/431report/
Eames, Ivo. "How Does Virtual Surround Work?" Sound on Sound. July 2004. (5/15/2007). http://www.soundonsound.com/sos/jul04/articles/ qa0704-5.htm?print=yes
Taub, Eric A. "The Sweet Deception of Virtual Sound." New York Times. 12/2/1999. (5/15/2007). http://query.nytimes.com/gst/fullpage.html? res=9805EFD81E3FF931A35751C1A96F958260
Vann's. "Getting 5.1 Surround from Two Speakers." (5/15/2007). http://www.vanns.com/shop/servlet/content/info/1131144368679/1
Wenzel, Elizabeth M. "Virtual Acoustics." AccessScience@McGraw-Hill. 11/23/2004. (5/15/2007).
Wong, Lawson. "Multi-Speaker vs. Virtual Surround." Popular Mechanics. July 2005. (5/15/2007). http://www.popularmechanics.com/technology/upgrade/1752292.html
Cite This!
Please copy/paste the following text to properly cite this HowStuffWorks.com article: