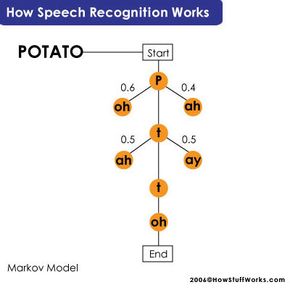
Today, when we call most large companies, a person doesn't usually answer the phone. Instead, an automated voice recording answers and instructs you to press buttons to move through option menus. Many companies have moved beyond requiring you to press buttons, though. Often you can just speak certain words (again, as instructed by a recording) to get what you need. The system that makes this possible is a type of speech recognition program -- an automated phone system.
You an also use speech recognition software in homes and businesses. A range of software products allows users to dictate to their computer and have their words converted to text in a word processing or e-mail document. You can access function commands, such as opening files and accessing menus, with voice instructions. Some programs are for specific business settings, such as medical or legal transcription.
Advertisement
People with disabilities that prevent them from typing have also adopted speech-recognition systems. If a user has lost the use of his hands, or for visually impaired users when it is not possible or convenient to use a Braille keyboard, the systems allow personal expression through dictation as well as control of many computer tasks. Some programs save users' speech data after every session, allowing people with progressive speech deterioriation to continue to dictate to their computers.
Current programs fall into two categories:
Small-vocabulary/many-users
These systems are ideal for automated telephone answering. The users can speak with a great deal of variation in accent and speech patterns, and the system will still understand them most of the time. However, usage is limited to a small number of predetermined commands and inputs, such as basic menu options or numbers.
Large-vocabulary/limited-users
These systems work best in a business environment where a small number of users will work with the program. While these systems work with a good degree of accuracy (85 percent or higher with an expert user) and have vocabularies in the tens of thousands, you must train them to work best with a small number of primary users. The accuracy rate will fall drastically with any other user.
Speech recognition systems made more than 10 years ago also faced a choice between discrete and continuous speech. It is much easier for the program to understand words when we speak them separately, with a distinct pause between each one. However, most users prefer to speak in a normal, conversational speed. Almost all modern systems are capable of understanding continuous speech.
Advertisement